机器学习
机器学习
监督式学习(supervised learning)
监督学习模型在看到大量包含正确答案的数据后,可以发现数据中产生正确答案的元素之间的关联,从而做出预测。
构成
Data 数据
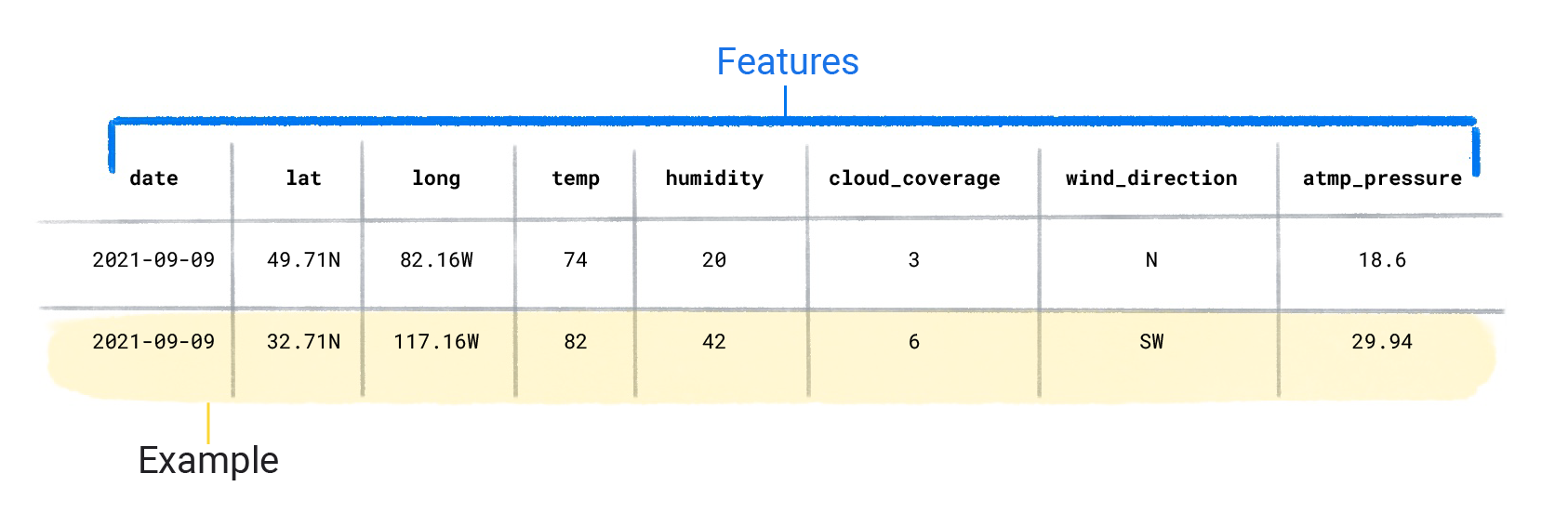
数据即数据集,由一个个数据组成,通常一个示例数据( examples)包含多个特征(features)和一个标签(label)
带标签的示例(labeled examples)

不带标签的示例(未标记示例,通常由模型根据特征预测标签)
Model 模型
- 在监督学习中,模型是一组复杂的数字集合,它定义了从特定输入特征模式到特定输出标签值的数学关系。模型通过训练来发现这些模式(patterns)。
Training 训练
在监督模型能够进行预测之前,必须先对其进行训练。训练模型时,我们需要提供一个包含已标注样本的数据集。模型的目标是找到根据特征预测标签的最佳方案。模型通过比较预测值和标签的实际值来找到最佳方案。基于预测值和实际值之间的差异(称为损失 (loss)),模型会逐步更新其方案。换句话说,模型学习特征和标签之间的数学关系,从而能够对未见过的数据做出最佳预测。
以下演示了如何训练模型:
步骤 1: 该模型接收一个带标签的示例并给出预测结果。
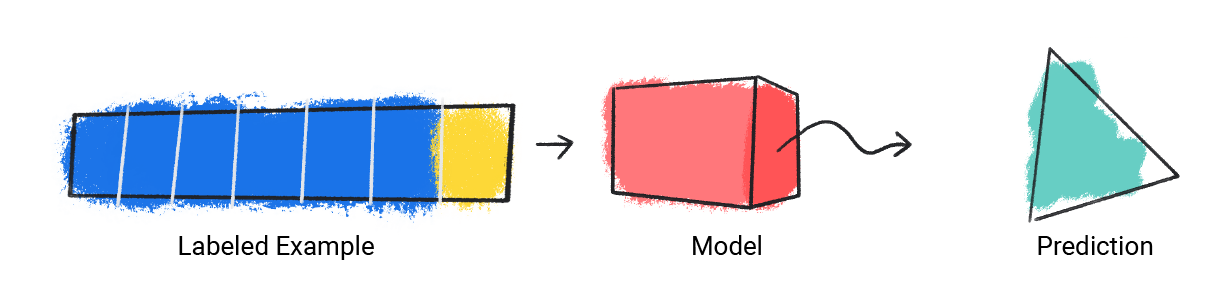
图 1. 机器学习模型根据标记示例进行预测。
步骤 2: 该模型将其预测值与实际值进行比较,并更新其解决方案(solution)。
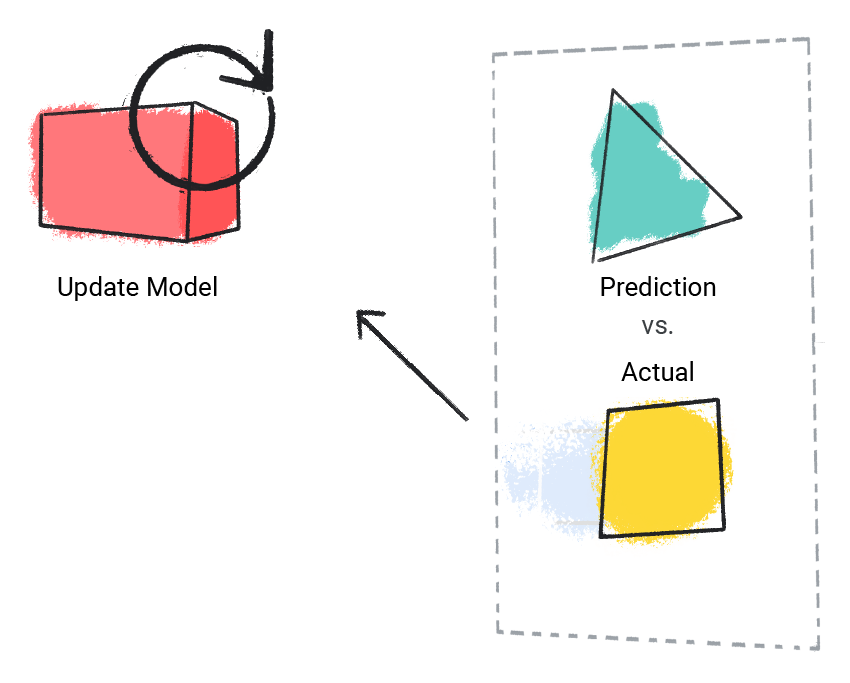
图 2. 机器学习模型更新其预测值。
步骤 3: 该模型对数据集中的每个标记示例重复(repeats)此过程。
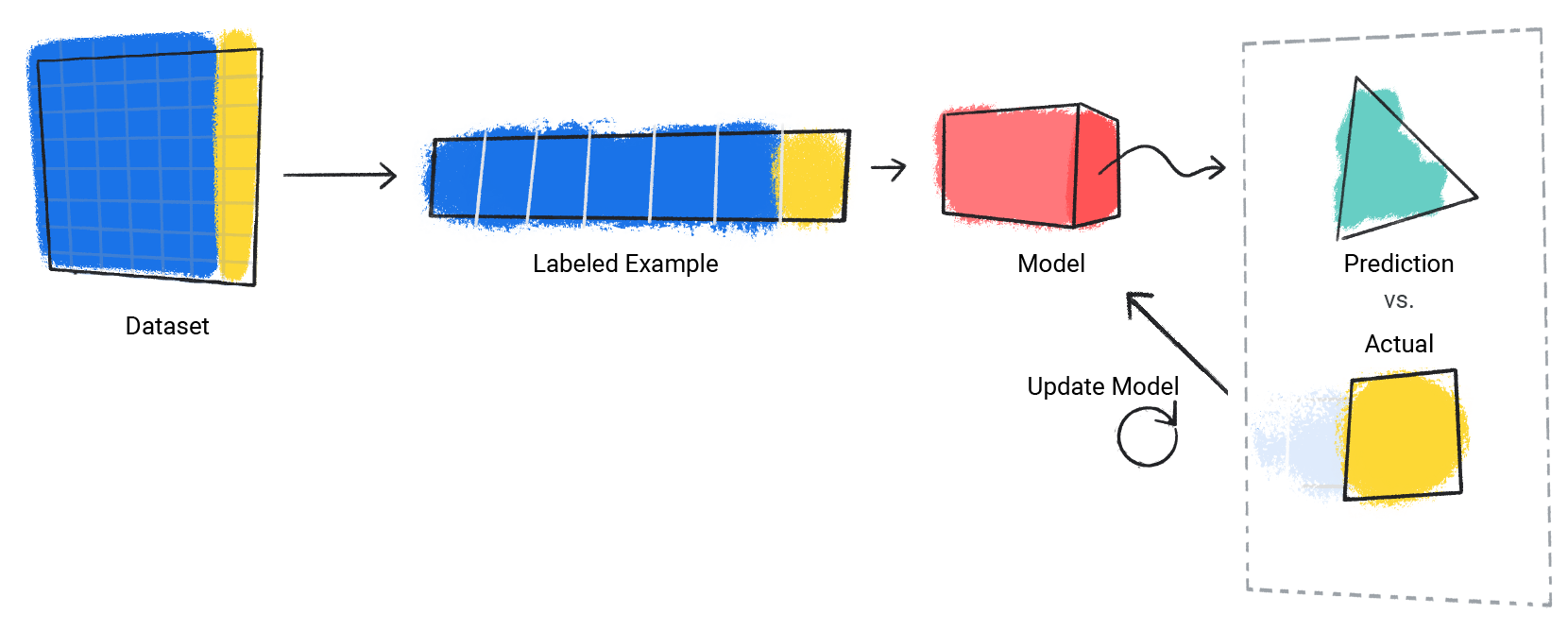
图 3. 机器学习模型更新其对训练数据集中每个标记示例的预测。
Evaluating 评估
我们评估训练好的模型,以确定其学习效果。评估模型时,我们使用带标签的数据集,但只向模型提供数据集的特征。然后,我们将模型的预测结果与标签的真实值进行比较。
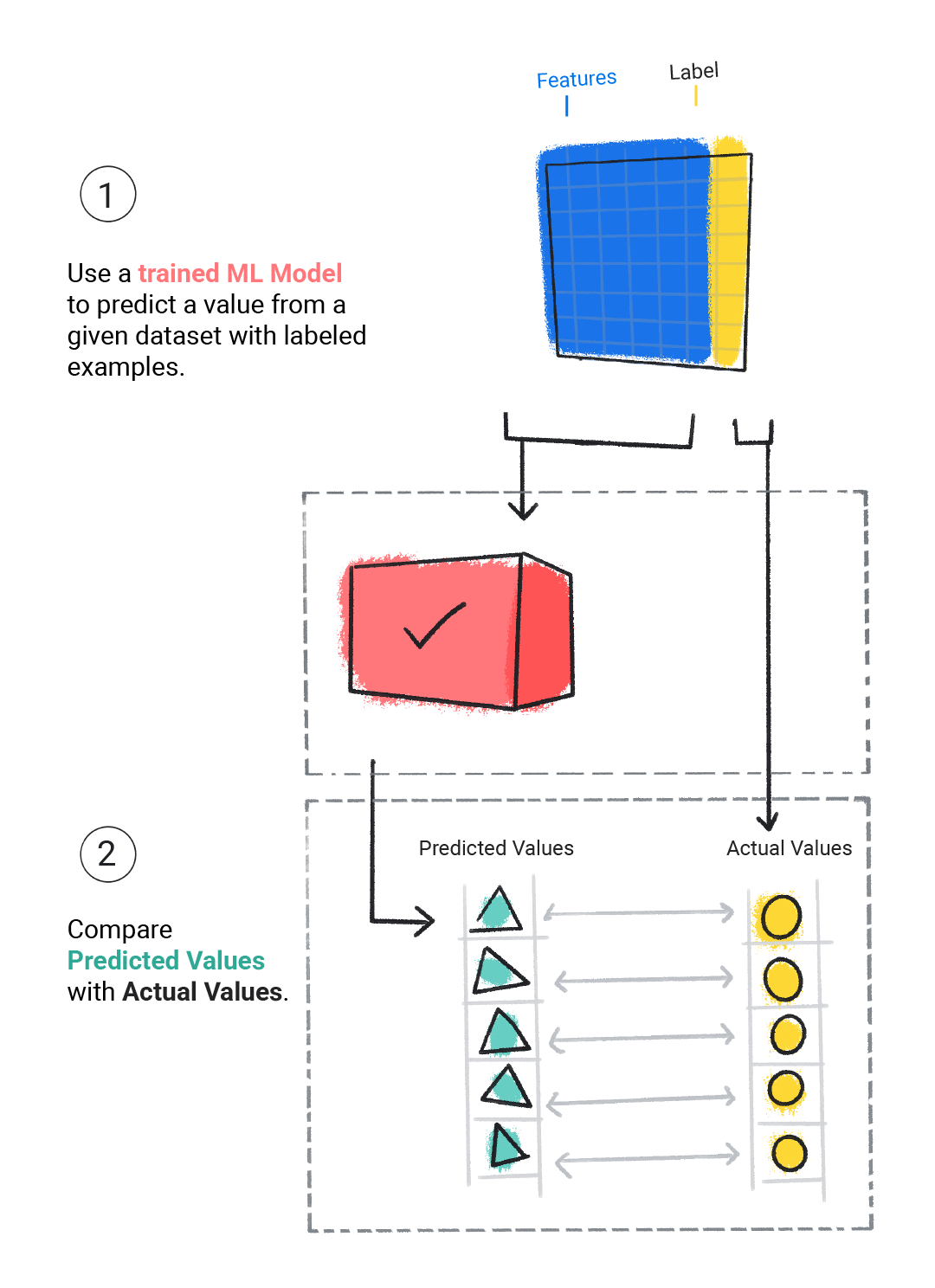
图 4. 通过比较 ML 模型的预测值与实际值来评估 ML 模型。
Inference 推理
- 一旦我们对模型评估结果感到满意,我们就可以使用 用于进行预测的模型,称为 对未标记示例进行推断 。以天气应用为例,我们会给模型提供当前的天气状况(例如温度、气压和相对湿度),它会预测降雨量。
回归(regression)
预测数值
| 场景 | 可能的输入数据 | 数值预测 |
|---|---|---|
| 未来房价 | 房屋面积、邮政编码、卧室和浴室数量、地块面积、抵押贷款利率、房产税率、建造成本以及该区域的待售房屋数量。 | 住宅的价格。 |
| 未来行程时间 | 历史路况信息(从智能手机、交通传感器、网约车和其他导航应用收集)、与目的地的距离以及天气状况。 | 到达目的地所需的时间(以分钟和秒为单位)。 |
线性回归(Linear regression)
模型(Model)
在机器学习中,线性回归模型的方程(equation)可以写成如下形式:
其中:
$y'$:预测标签,即输出。$b$:模型的偏差。偏差与直线方程中的 y 轴截距对应,在机器学习中有时也写作$w_0$。偏差是模型在训练过程中学习得到的一个参数。$w_1$:特征的权重。权重与直线方程中的斜率对应,也是模型在训练过程中学习得到的一个参数。$x_1$:一个特征,即输入。
损失(Loss)
Loss is a numerical metric that describes how wrong a model’s predictions are. Loss measures the distance between the model’s predictions and the actual labels. The goal of training a model is to minimize the loss, reducing it to its lowest possible value. 损失是一种数值指标,用于描述模型的预测与实际情况的偏差程度。损失用于衡量模型预测与实际标签之间的距离。训练模型的目标是尽可能降低损失,使其达到最低值。
损失距离(Loss Distance): 损失函数应该关注的是值之间的距离,而不是方向。常见的距离取法:1. 取绝对值 2. 平方
损失类型(Type of loss):
Loss type 损失类型 Definition 定义 Equation 方程 L1 loss L1 损失 The sum of the absolute values of the difference between the predicted values and the actual values. 预测值与实际值之差的绝对值之和。 Mean absolute error (MAE) 平均绝对误差 The average of L1 losses across a set of N examples. 在 N 个样本中 L1 损失的平均值。 L2 loss L2 损失 The sum of the squared difference between the predicted values and the actual values. 预测值与实际值之差的平方和。 Mean squared error (MSE) 均方误差 The average of L2 losses across a set of N examples. 在 N 个样本中 L2 损失的平均值。 Root mean squared error (RMSE) 均方根误差 The square root of the mean squared error (MSE). 均方误差(MSE)的平方根。 When choosing the best loss function, consider how you want the model to treat outliers. For instance, MSE moves the model more toward the outliers, while MAE doesn’t. L2 loss incurs a much higher penalty for an outlier than L1 loss. For example, the following images show a model trained using MAE and a model trained using MSE. The red line represents a fully trained model that will be used to make predictions. The outliers are closer to the model trained with MSE than to the model trained with MAE. 选择最佳损失函数时,要考虑模型如何处理异常值。例如,均方误差 (MSE) 会使模型更倾向于异常值,而平均绝对误差 (MAE) 则不会。L2 损失对异常值的惩罚远高于 L1 损失。例如,下图分别展示了使用 MAE 和 MSE 训练的模型。红线代表一个已完全训练好的模型,该模型将用于进行预测。异常值更接近使用 MSE 训练的模型,而不是使用 MAE 训练的模型。
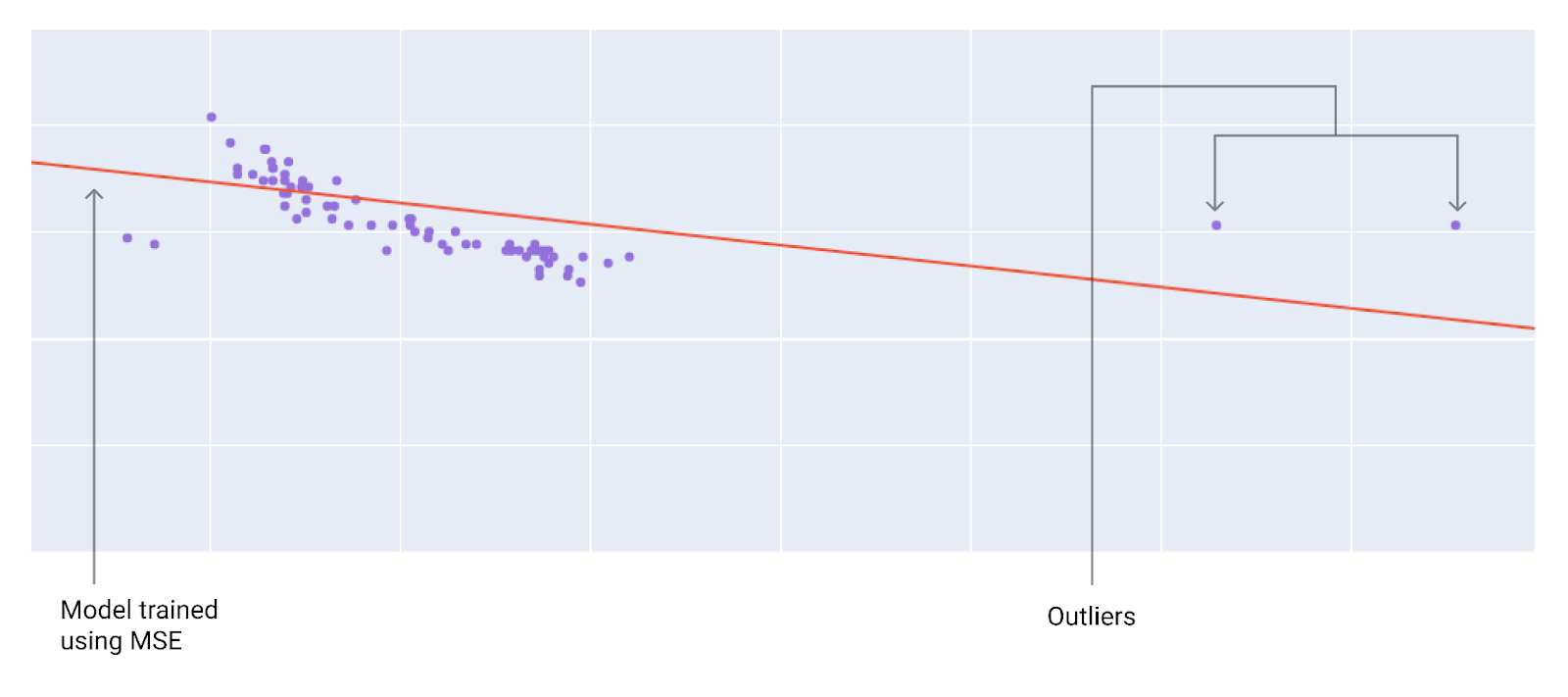
Figure 9. MSE loss moves the model closer to the outliers. 图 9. MSE 损失使模型更接近异常值。
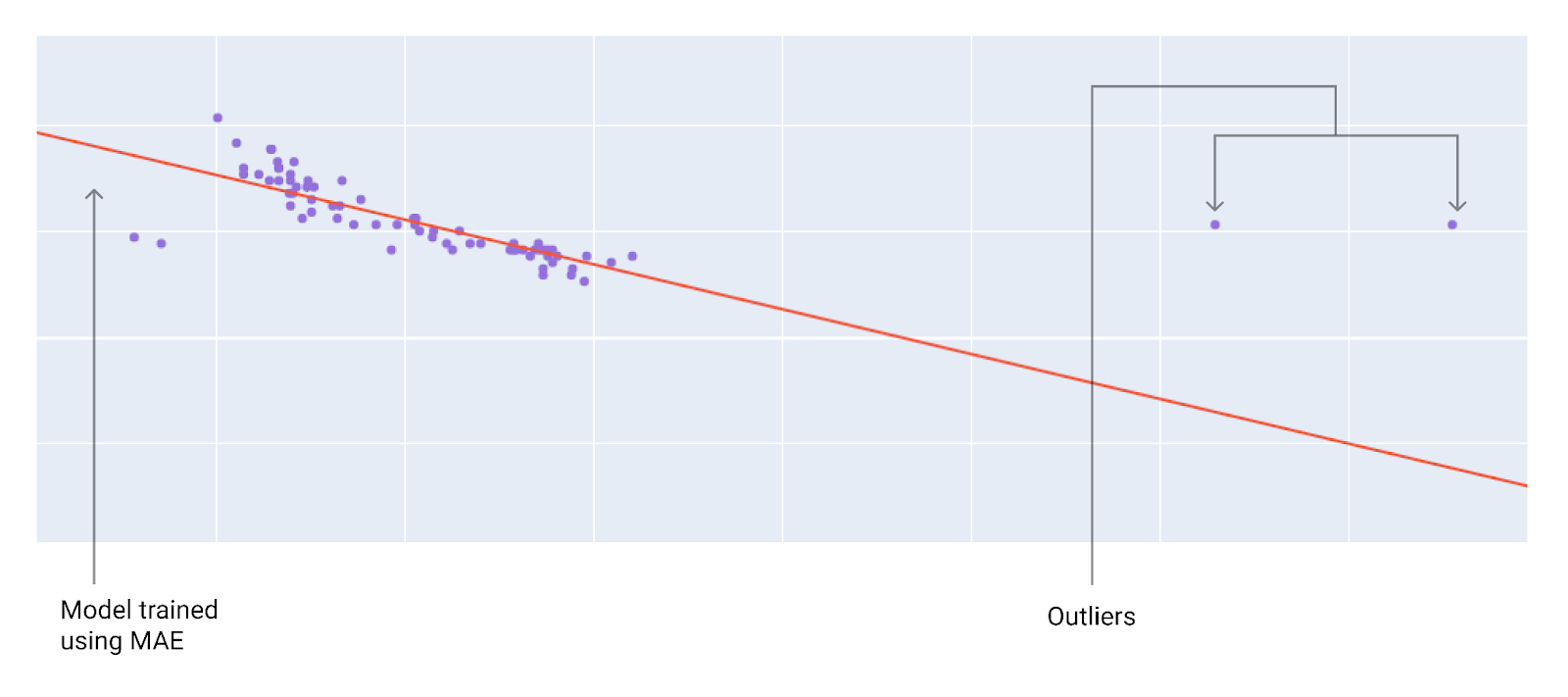
Figure 10. MAE loss keeps the model farther from the outliers. 图 10. MAE 损失使模型远离异常值。
Choose MSE: 选择 MSE:
- If you want to heavily penalize large errors. 如果你想对重大错误进行严厉惩罚。
- If you believe the outliers are important and indicative of true data variance that the model should account for. 如果您认为异常值很重要,并且能够反映模型应该解释的真实数据差异。
Note: The mathematical properties of MSE often make optimization smoother. Root Mean Squared Error (RMSE) is often used to get the error back into the same units as the label. 注: 均方误差 (MSE) 的数学特性通常能使优化过程更加平滑。均方根误差 (RMSE) 通常用于将误差单位转换回与标签相同的单位。
Choose MAE: 选择 MAE:
- If your dataset has significant outliers that you don’t want to overly influence the model. MAE is more robust. 如果你的数据集存在显著的异常值,而你不希望这些异常值对模型产生过大的影响,那么平均绝对误差(MAE)则更为稳健。
- If you prefer a loss function that is more directly interpretable as the average error magnitude. 如果您更喜欢可以直接解释为平均误差幅度的损失函数。
In practice, your metric choice can also depend on the specific business problem and what kind of errors are more costly. 在实践中,指标的选择还可以取决于具体的业务问题以及哪些类型的错误代价更高。
梯度下降(Gradient descent)
逻辑回归(Logistic regression )
分类(classification)
分类模型可预测某事物属于某个类别的可能性。与输出为数值的回归模型不同,分类模型输出的值用于指明某事物是否属于特定类别。例如,分类模型用于预测电子邮件是否为垃圾邮件,或照片中是否包含猫。
分类模型分为两组:二元分类和多类别分类。二元分类模型会输出仅包含两个值的类中的一个值,例如,输出 rain 或 no rain 的模型。多类别分类模型会输出一个值,该值来自包含两个以上值的类别,例如,可以输出 rain、hail、snow 或 sleet 的模型。
非监督式学习
非监督式学习模型旨在识别数据集中的有意义模式。例如,许多非监督式学习模型都依赖于一种称为聚类的技术,将类似的数据整理成组(“聚类”)。
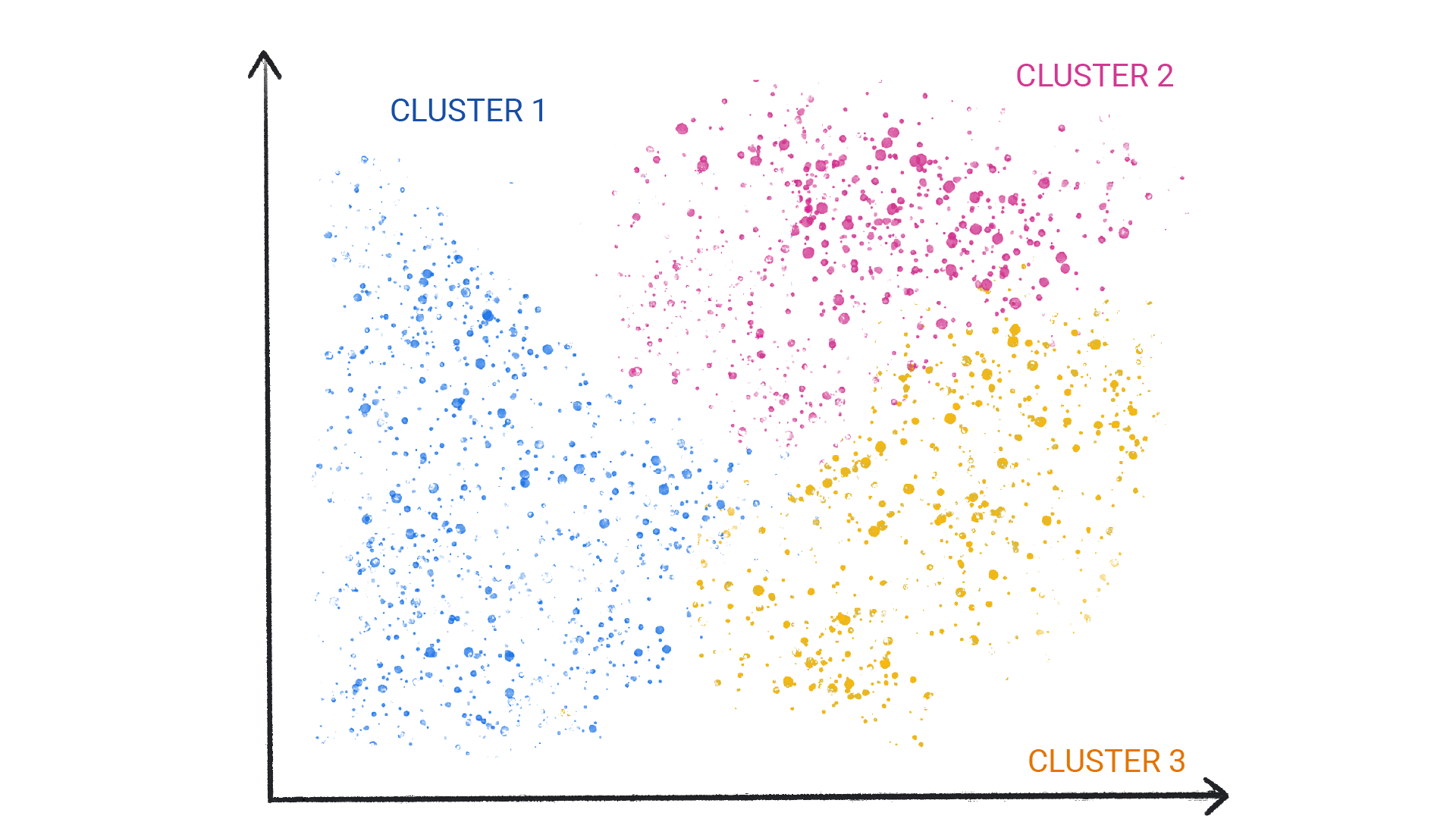
图 1. 一种用于对相似数据点进行聚类的机器学习模型。
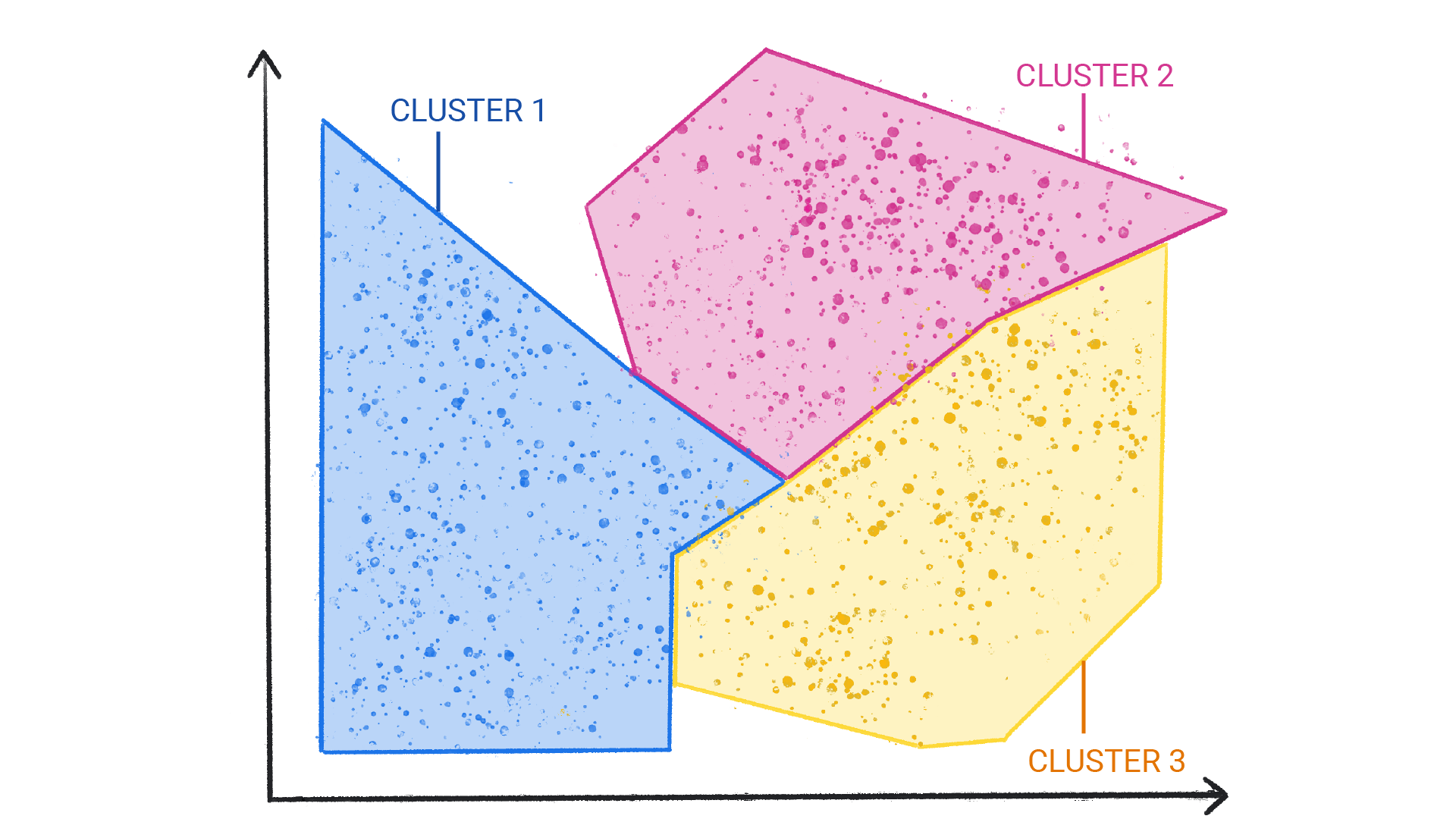
图 2. 具有自然分界的集群组。
聚类与分类的不同之处在于,聚类中的类别不是由您定义的。例如,非监督式模型可能会根据温度对天气数据集进行聚类,从而揭示定义季节的细分。然后,您可能会尝试根据对数据集的了解来命名这些聚类。
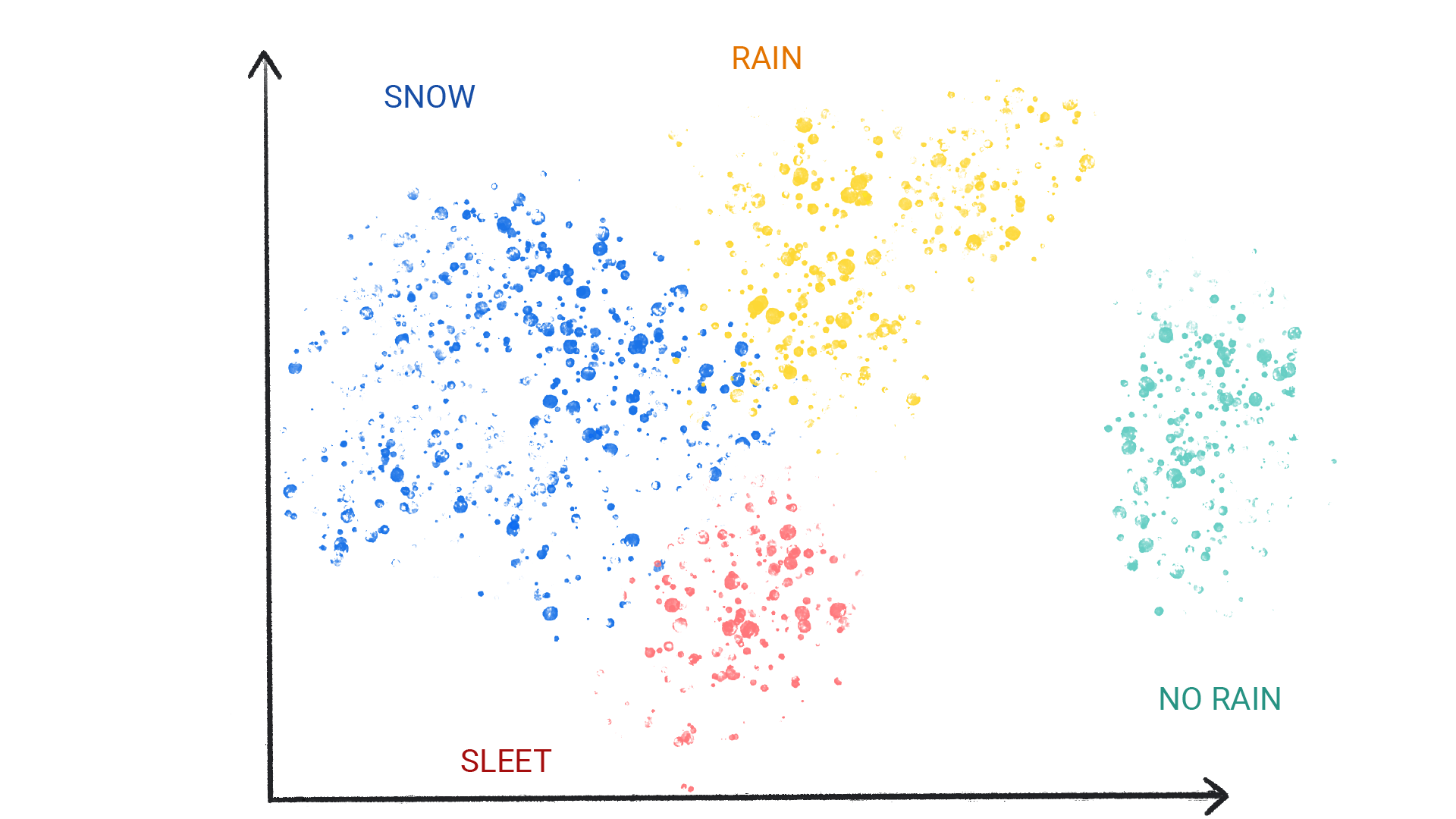
图 3. 一种用于聚类相似天气模式的机器学习模型。
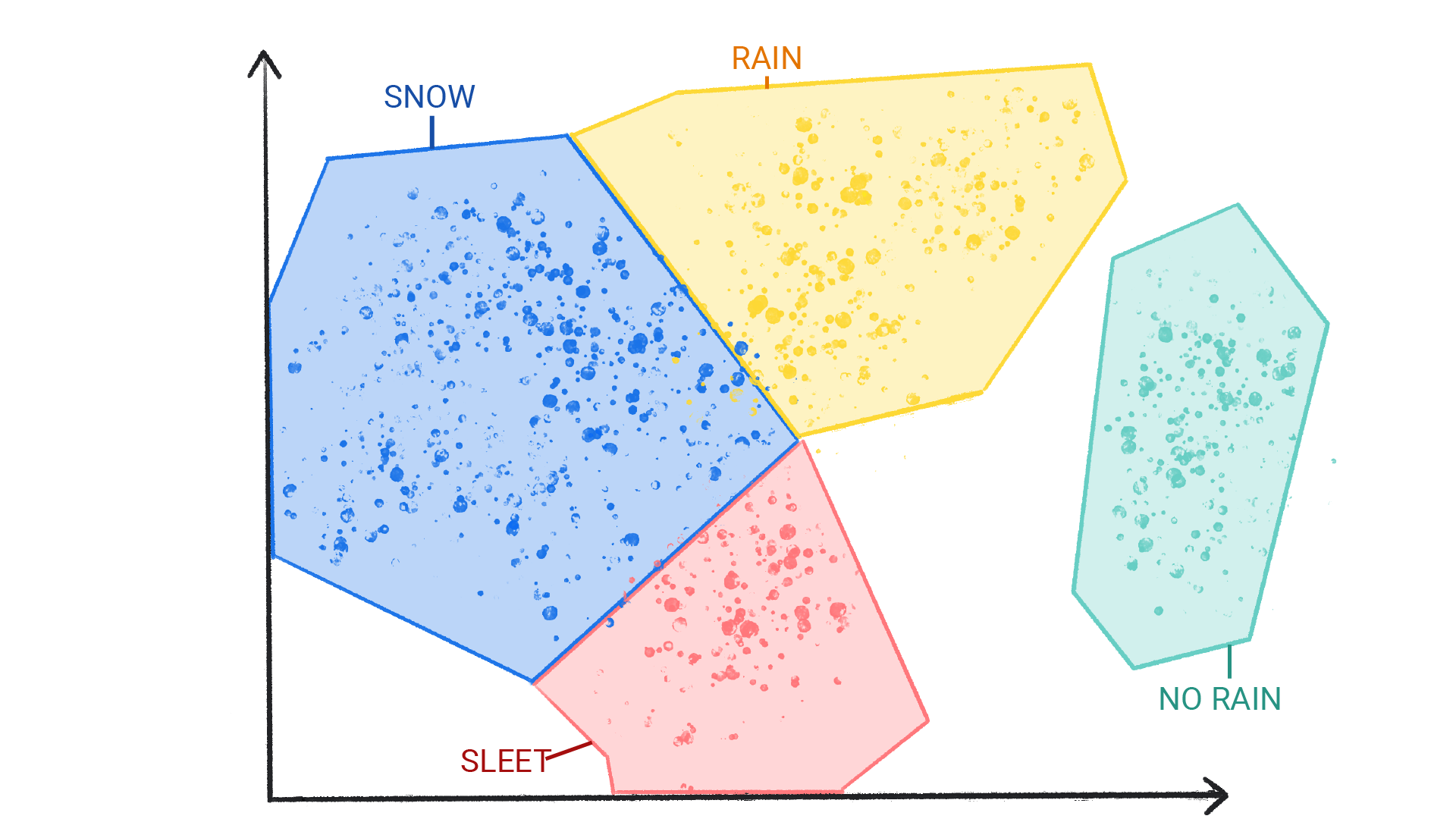
图 4. 标记为下雪、雨夹雪、下雨和不下雨的天气模式聚类。
强化学习
强化学习模型通过根据在环境中执行的操作获得奖励或惩罚来进行预测。强化学习系统会生成一项政策,用于定义获得最多奖励的最佳策略。
强化学习用于训练机器人执行任务,例如在房间内走动,以及训练软件程序(例如 AlphaGo)玩围棋。
生成式AI
生成式 AI 是一类可根据用户输入生成内容的模型。例如,生成式 AI 可以创作独特的图片、音乐作品和笑话;还可以总结文章、说明如何执行任务或编辑照片。
生成式 AI 可以接受各种输入,并生成各种输出,例如文本、图片、音频和视频。它还可以采用这些元素的组合。例如,模型可以接受图片作为输入,并生成图片和文本作为输出;也可以接受图片和文本作为输入,并生成视频作为输出。
我们可以根据生成式模型的输入和输出来讨论它们,通常写为“输入类型”-“输出类型”。例如,以下是生成式模型的部分输入和输出列表:
- 文本到文本
- 文本到图像
- 文本到视频
- 文生代码
- 文字转语音
- 图片和文生图
生成式 AI 如何运作?从宏观层面来看,生成模型会学习数据中的模式,以生成新的但类似的数据。生成式模型如下所示:
- 通过观察他人的行为和说话风格来学习模仿他人的喜剧演员
- 通过研究大量特定风格的画作来学习以该风格绘画的艺术家
- 通过聆听特定音乐团体的众多音乐来学习如何模仿该团体声音的翻唱乐队
为了生成独特而富有创意的输出,生成式模型最初采用非监督式方法进行训练,即模型学习模仿其训练所用的数据。有时,模型会使用与模型可能需要执行的任务(例如总结文章或编辑照片)相关的特定数据,通过监督式学习或强化学习进一步训练。